前言算法流程RPN(Region Proposal Network)anchor训练数据采样RPN Multi-task loss分类损失边界框回归损失Fast R-CNN Multi-task lossFaster R-CNN训练Faster R-CNN框架
前言
原论文地址:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
由于SS算法的时间花销大,因此Faster R-CNN就是在Fast R-CNN的基础上改进得到候选框的方法,即使用RPN算法替代SS算法。
算法流程
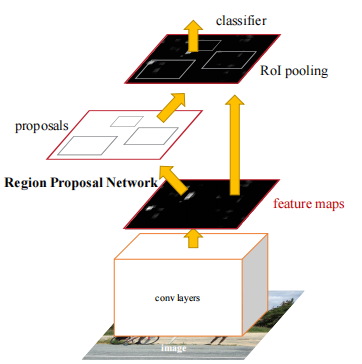
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
Faster R-CNN 即是 RPN + Fast R-CNN
流程图:
RPN(Region Proposal Network)
RPN 网络结构:
 在特征图feature map上有一个滑动窗口(红色框),每滑动到一个位置上就生成一个行向量,是256维的(使用ZF网络生成的Backbone的深度channel是256,如果使用VGG16,那这里就是512),在这个向量的基础上通过两个连接层分别获得该区域的目标概率以及边界框回归参数。上图中表示了会有 2k 个目标概率,这个 k 都是针对有 k 个 anchor boxes的(anchor box下面会讲)。为什么是 2k 呢?因为这是对每个anchor box生成两个概率,分别是前景(框内包含检测目标)的概率和背景的概率;同样针对有 k 个 anchor box会生成 4k 个回归参数,即Fast R-CNN中提到的
在特征图feature map上有一个滑动窗口(红色框),每滑动到一个位置上就生成一个行向量,是256维的(使用ZF网络生成的Backbone的深度channel是256,如果使用VGG16,那这里就是512),在这个向量的基础上通过两个连接层分别获得该区域的目标概率以及边界框回归参数。上图中表示了会有 2k 个目标概率,这个 k 都是针对有 k 个 anchor boxes的(anchor box下面会讲)。为什么是 2k 呢?因为这是对每个anchor box生成两个概率,分别是前景(框内包含检测目标)的概率和背景的概率;同样针对有 k 个 anchor box会生成 4k 个回归参数,即Fast R-CNN中提到的
anchor
 如上图,左图为原图,右图为特征图,每一个方格就是一个像素pixel。首先在原图上找到特征图中3×3窗口中心对应的点:设横向为x轴,纵向y轴,用原图的宽度除以特征图的宽度并取整,就得到了步长stride,如图窗口中心的x坐标为3,那么原图中对应的x坐标就为 stride×3,y坐标同理。以得到的原图中的xy坐标点作为中心,来计算出 k 个anchor boxes(每个anchor box都有固定的大小及长宽比例),如图 k 为3时,对应的就是红、蓝、黄个框。
如上图,左图为原图,右图为特征图,每一个方格就是一个像素pixel。首先在原图上找到特征图中3×3窗口中心对应的点:设横向为x轴,纵向y轴,用原图的宽度除以特征图的宽度并取整,就得到了步长stride,如图窗口中心的x坐标为3,那么原图中对应的x坐标就为 stride×3,y坐标同理。以得到的原图中的xy坐标点作为中心,来计算出 k 个anchor boxes(每个anchor box都有固定的大小及长宽比例),如图 k 为3时,对应的就是红、蓝、黄个框。

如上图,根据特征图对应原图得到了这几个黄色框,这就可能包括我们想要检测的目标。

- cls即为得到的目标概率分数(每2个为一组,对应同一个anchor,分别是 是背景的概率 和 是前景的概率),k 个 anchor 就共有 2k 个 score。
 假设cls中第一块对应的是上图黄色框,那么这个框是背景的概率为0.1,是前景的概率为0.9(这里并没有分类,只要是我们需要检测的目标就是前景)
假设cls中第一块对应的是上图黄色框,那么这个框是背景的概率为0.1,是前景的概率为0.9(这里并没有分类,只要是我们需要检测的目标就是前景) - reg即为边界框回归参数,每4个一组,
论文中对于anchor共给出了三种尺度(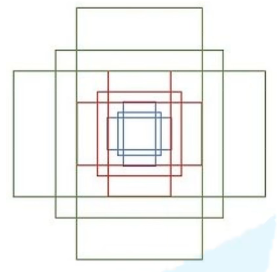 对于一张1000×600×3的图像,大约有60×40×9(20k)个anchor,忽略跨越便捷的anchor以后,剩下约6k个×。对于RPN生成的候选框之间存在大量重叠,基于候选框的 cls 得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩 2k 个候选框。
对于一张1000×600×3的图像,大约有60×40×9(20k)个anchor,忽略跨越便捷的anchor以后,剩下约6k个×。对于RPN生成的候选框之间存在大量重叠,基于候选框的 cls 得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩 2k 个候选框。
扩展——CNN感受野
ZF感受野:171 VGG感受野:228
感受野即是 3×3 滑动窗口还原到原图的大小,但原图是256的,为什么感受野比256小却又能识别出来呢?作者认为通过小的感受野去识别比他大的边界框是有可能的,类似见微知著的效果,看到了一部分就能猜出目标完整的一个区域。实际上,这种方法也确实是有效的。
下面给出计算ZF网络feature map中3×3滑动窗口在原图中感受野的大小:
 VGG相对比较复杂。
VGG相对比较复杂。
训练数据采样
上文说到对于一张图像会生成上万个anchor,但并不都作为训练样本,只采样256个anchor并分为正样本和负样本,比例大概为1:1,若正样本数不足128个,则使用负样本补充。
正样本:anchor与真实框(ground-truth box)的 IoU 大于0.7 / anchor与某个真实框(ground-truth box)的IoU是最大的(这句话的意思就是假如有某个ground-truth与所有anchor的IoU为0.1,0.5,0.3,即都小于0.7,那么这个0.5分数的anchor也会成为正样本),这两种条件都被判别成正样本。
负样本:与所有ground-truth的IoU都小于0.3的anchor即为负样本。
正负样本以外的样本全部丢弃。
RPN Multi-task loss

分类损失

虽然这里分类是分两类(区别前景与背景)的,但是损失实际上用的是多分类损失,因为cls生成的是 2k 个分数,如果用的是二分类,那么 k 个分数就可以了(趋于0是背景,趋于1是前景)。
边界框回归损失
与Fast R-CNN基本相同
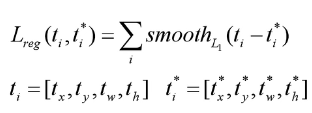
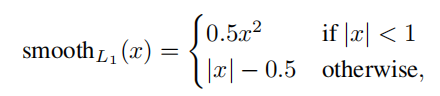
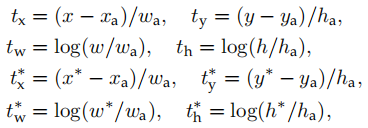
Fast R-CNN Multi-task loss
和上一篇文章中的内容一致,去看Fast R-CNN的内容即可。
Faster R-CNN训练
直接采用RPN Loss + Faster R-CNN Loss的联合训练方法(两个Loss直接相加)
原论文中采用分别训练RPN以及Fast R-CNN的方法
- 利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数;
- 固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议框去训练Fast RCNN网络参数。
- 固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层以及全连接层参数
- 同祥保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数。最后RPN网络与Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络。
Faster R-CNN框架
 将四部分融合到一个网络中训练,实现端对端的训练过程。
将四部分融合到一个网络中训练,实现端对端的训练过程。
参考来源:1.1Faster RCNN理论合集